
What do noindex meta tag and robots.txt have in common? They both sound like something only techy people should be worried about.
But on a more serious note…
One other thing these directives have in common is they determine whether search engines can find your content and if that page gets indexed. So they’re worth paying attention to.
That’s why, in this post, we’ll break down when to use noindex vs robots.txt and the differences between them. Let’s start with what they mean.
A noindex tag tells search engines to exclude a page from appearing in search results. It is implemented on an individual page and is visible within the <head> section of the page’s source code like in the image below.
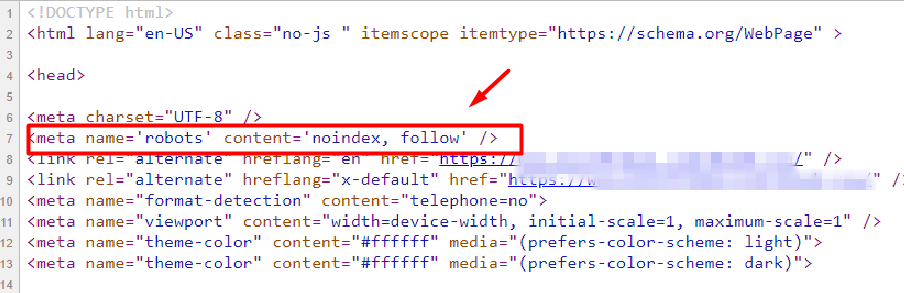
As in the image, an example of a noindex code is: <meta name=’robots’ content=’noindex, follow’ />. If you don’t see this code on your page, it can be indexed. You can also implement it through an HTTP response header. Whichever way you choose, once search engines crawl the page and extract this tag, the web page won’t appear in search results. If the page was indexed in the past, it would be dropped entirely.
The goal of most content creation efforts is to get your pages indexed and in front of as many people as possible. That said, you might be wondering: in what cases would I want to prevent my content from appearing in search results?
When you have low-quality pages or thin content that have no SEO value but is important for user experience, it makes sense to keep these pages off search results. A noindex tag can help you do that. This is best if crawl budget isn’t an issue for your website and you don’t mind if these pages are crawled.
Also, if you have goal pages or campaign landing pages where random visitors could skew your reporting data, it’s best to noindex these pages and not link them from anywhere on your site.
Examples of web pages to keep off search results are:
While these pages won’t appear in search results, search engine bots can still crawl them. If you want to control crawling, let’s look at robots.txt.
Robots.txt controls crawling. It instructs search engine crawlers where they shouldn’t go on a website. It also specifies where your sitemap can be found. Rather than specific pages, you can block off access to sections of a website or resources such as scripts. Well, the less important ones.
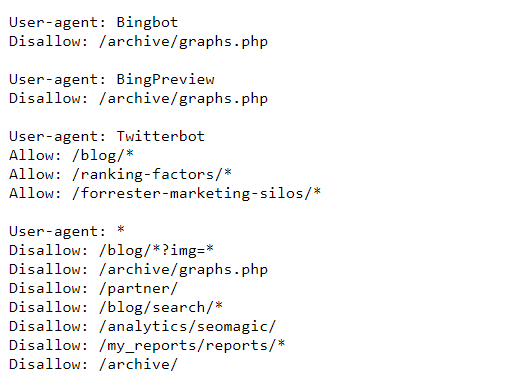
Just like in the image above, a robots.txt file would have instructions like this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Major search engines like Google and Bing would obey these directives. However, other web crawlers and malicious bots may not. Also, even though the pages won’t be crawled, they can still get indexed. So it’s important to avoid using robots.txt to protect sensitive information on your website.
To learn more about how to control crawling, read our guide on understanding robots.txt.
Short answer: use robots.txt to prevent search engines from accessing specific directories on your website.
Let me give more context—usually, not all websites need a robots.txt file. This is because crawlers would usually find and index any valuable page on such a website. But there are cases when a robots.txt file is important. This includes:
If you’re still confused about when to use noindex meta tag vs noindex, think about this: between having unimportant pages crawled vs keeping them off search results, which is more important to you right now?

The difference is that a noindex tag is used to stop your pages from appearing in search results while robots.txt tells search engine bots which directories or files it should or shouldn’t crawl.
This means that if you use a noindex tag, your pages won’t get indexed BUT would still be crawled. On the other hand, if you use robots.txt, the specified files won’t be crawled BUT they might get indexed. The two directives also differ in the level of scope. Here’s a breakdown of how they differ:
No, you shouldn’t combine noindex tag and robots.txt. You’ve likely surmised that since one of these directives covers indexing and the other covers crawling, it would make sense to combine both to achieve the expected result. However, that’s far from what would happen.
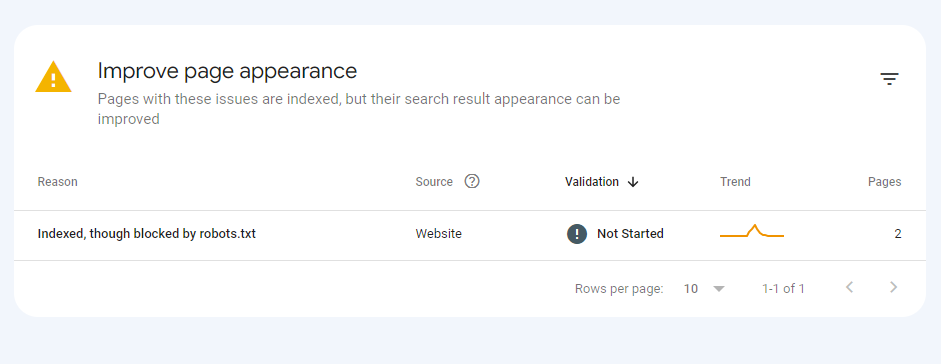
If you keep crawlers from accessing a page using robots.txt and then implement a noindex tag, the page might get indexed. This is common when the pages are linked elsewhere on the web. When that happens, you would see a new indexing warning titled “Indexed though blocked by robots.txt” on the Google Search Console. An example is the image below:
Why?
For search engines to see the NOINDEX tag, they must be able to CRAWL a page and read the code. If they CANNOT CRAWL the page, the noindex tag is assumed not to be on the page. Thus, the page would get INDEXED.
Let’s imagine for a second the wrongly indexed page is your staging site. The staging site could compete with your main site for traffic and rankings. This is in addition to the poor user experience when visitors land on the test site rather than the real one. So, it’s best not to mix them.
See? When to use noindex or robots.txt depends on what you intend to achieve. Whichever one you choose, you can only control one directive.
So, if you aim to stop a page from being indexed, use the noindex tag. But if you’re more interested in keeping off crawlers from some pages or files so the more important directories would be crawled, then robots.txt is what you need. Don’t combine both as a means to block a page from indexing and crawling—it would backfire!
If you need help optimizing your website’s indexing or crawling, don’t hesitate to reach out to our specialists.

{kind=link}
{kind=link}