
Fear not the techy-sounding robots.txt file, my friends. I’ve created a comprehensive, easy-to-understand guide to the robots.txt file for the average inbound marketer – no developer knowledge required.
The robots.txt file is a document stored in the root directory of a website that tells search engine crawlers and other robots how to and how not to crawl and index the folders and/or individual pages of a website. Some people use this to keep people out of private, password-secured areas of a website. Others use the file to help combat duplicate content issues, often in combination with rel=canonical or noindex tags.

Using robots.txt – that filename is case-sensitive, by the way – you can tell search engine crawlers not to crawl certain part of your website by disallowing certain subfolders. However, the robots.txt file must be treated very carefully so you don’t accidentally block search engine bots from crawling all of your site! Please consult a professional if you are unsure. Some sites that do not plan to restrict access to certain content may even choose not to have a robots.txt file at all. This file is not designed for security purposes, though – that is a common misconception. Hackers and malicious crawlers do not care about restrictions set in your robots.txt file.
One robots.txt file manages the entire site, unless you have a section of your site in a subdomain (not a subfolder). So for example, if you have both yoursite.com and subdomain.yoursite.com, that may call for two separate robots.txt files. But if you have yoursite.com and yoursite.com/subfolder, only the one main robots.txt file is necessary.
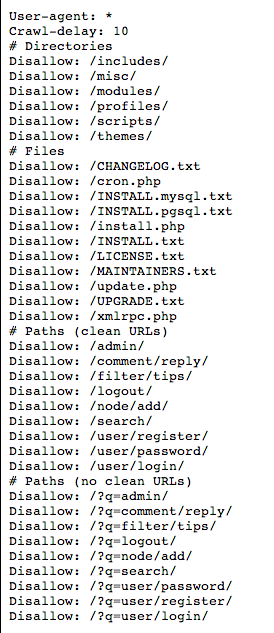
ROBOTS.TXT FROM WHITEHOUSE.GOV’S DRUPAL SITE
The characters used in a robots.txt file are often the same characters used in Regular Expressions (commonly called RegEx), which bots the pattern to match for URLs. The character # is not quite the same. See below.
That’s about it. Simple so far, right? We hope so.
The Meta Robots tag is used on a page-by-page basis to tell bots to not index a page, and/or to not crawl and follow the links on the page. As with the robots.txt file, the search engines don’t have to obey this, but they generally try to play nice. Because the meta robots tag is used on a specific, individual page, they tend to be obeyed more consistently by Google and Bing. But bad guys like malware bots flat out don’t care. Sorry dudes.
In action, this tag typically looks like this on a page: <meta name=”robots” content=”noindex,nofollow”>. It’s placed in the <head> section of a page. Easy peasy lemon squeezy.
The “noindex” part of this advises search engines not to include the page in their search indexes. The “nofollow” part of this advises them not to crawl and follow the links on the page. (The opposite – “index,follow” – is already the default, so using that directive would be redundant. Don’t bother. The meta robots tag can allow bots to crawl pages and follow links while still disallowing pages from being indexed in organic search results.
About 56% of my bot traffic in this example is dumped into an “Unknown-Robot” source category, I’m afraid. But below is a short list of the most common friendly search bot user agents I’m familiar with seeing crawl my own website, but there are many, many others.
By the way, check out this flipping sweet article from Adrian Vender about how to set up a Google Analytics profile that tracks bot traffic. That’s how we have the percentage above. We gave it a whirl on this site and it’s pretty eye-opening! We get 6x to 11x more bot traffic than we get regular traffic. Interestingly, we get consistent spikes on weekends.
Update Apr. 2016 – Google has switched their smartphone user-agent from Apple iPhone/Safari to Android/Chrome. Read more here.
The most common mistake in the robots.txt file is disallowing the crawling of pages you didn’t mean to disallow. This typically happens when someone disallows an entire subfolder on accident by leaving it open-ended. So when you tell user-agents in the robots.txt file to “Disallow: /admin/” from being crawled and indexed, that will disallow the page /admin, but also all pages within that /admin/ subfolder on your site. Make sure that’s what you really want to do, otherwise be sure to close the URL. So in this example, you would use “Disallow: /admin$” if you only wanted to block that specific URL.
The other big error we see with robots.txt is when people use it as a security measure. The robots.txt file is not an adequate means of securing your site. If you put the directories you want to keep secret in the disallow list of your file, it’s basically saying, “Hey, hackers! I drew you a map to where we don’t want you.” Don’t do that. Malware bots and email address harvesters don’t care that your robots.txt file tells them to stay out. Robots.txt is a tool to keep redundant, duplicate or unimportant content on your site from being crawled and indexed. But do not leave your highly secret and sensitive data unprotected by relying on robots.txt alone for this task.
Even if you disallow crawling of a certain URL in robots.txt for all user agents, the page could still potentially show up in search results. The robots.txt is an incredibly valuable tool that tells crawlers what they should and should not access on your site – but it’s not perfect. The robots.txt file can help you save crawl bandwidth from the get-go, but to be more certain that a page does not show up in organic search results, consider using the meta robots tag at the page level instead.
The reason robots.txt may not be the ideal solution is that if a particular piece of content gets tons of visits or has many inbound links, Google and Bing may think they know better and not obey the tag. The robots.txt file tells bots to stop crawling in their tracks, but you should likely use the “noindex” Meta Robots tag at the page level instead to advise search engines to drop the page entirely from their index.
Much like using the robots.txt file, be extra careful using the noindex tag, and use it only if you are positive you do not want the page to show up in the search index. Search engines have said they do their best to obey this “noindex” Meta Robots tag.
Because robots.txt can be a little tricky, there a handful of validator tools or file checkers we recommend to help make sure you do the job right and don’t cause unintended consequences. But if you are concerned at all about executing this properly and accidentally hiding your entire site from search engines and their searchers, please contact your friendly neighborhood SEO.
There is a lot of material out there about how to use robots.txt effectively. Here is a little recommended reading if you want to become a true expert and master the robots.txt file. In no particular order:


{kind=link}
{kind=link}
{kind=link}